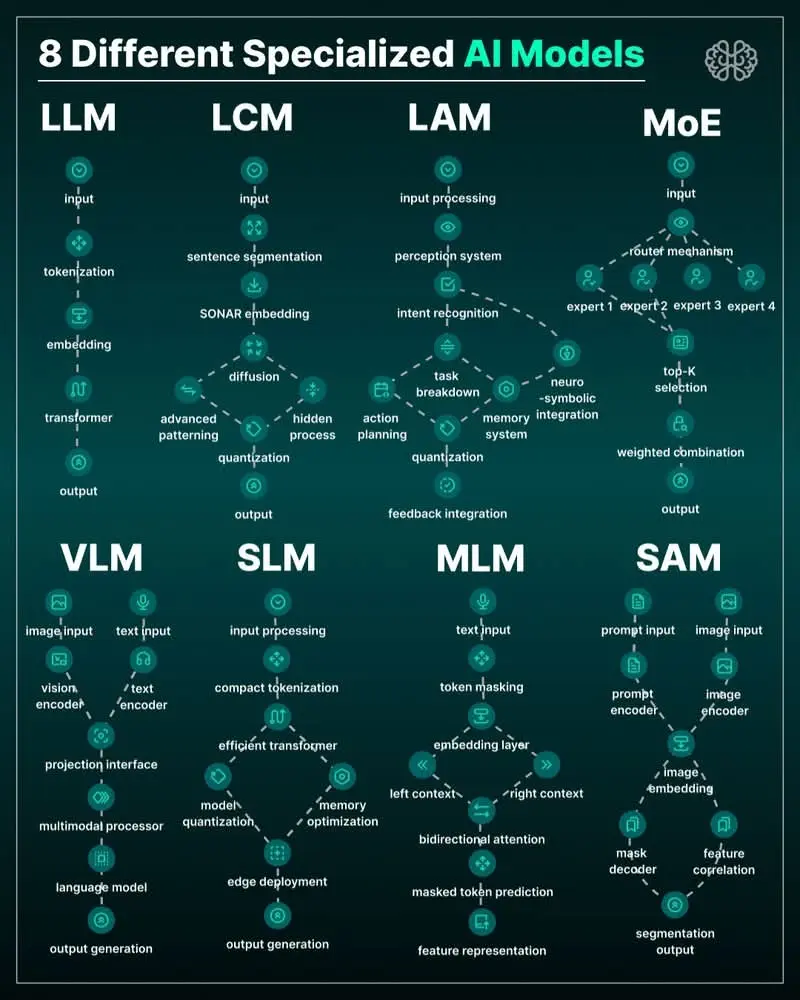
L’ère des modèles d’IA monolithiques et généralistes laisse progressivement place à une nouvelle génération d’architectures spécialisées. Alors que le grand public connaît principalement les LLM (Large Language Models) comme ChatGPT, une véritable révolution silencieuse est en cours dans les laboratoires de recherche et les entreprises technologiques. Huit types distincts de modèles d’IA spécialisés émergent, chacun optimisé pour des tâches spécifiques, offrant des performances supérieures, une efficacité accrue et des capacités jusqu’alors inaccessibles.
Cet article pédagogique explore en profondeur ces huit architectures, dévoilant comment elles fonctionnent, pourquoi elles sont nécessaires et comment elles transforment l’industrie de l’intelligence artificielle.
1. LLM (Large Language Models) : Les Généralistes du Langage
Architecture Fondamentale
Les LLM représentent la pierre angulaire de l’IA conversationnelle moderne. Leur architecture suit un pipeline sophistiqué :
text
Input → Tokenization → Embedding → Transformer Blocks → Output Generation
Tokenization : Le texte est décomposé en unités significatives (tokens), pouvant représenter des mots entiers, des syllabes ou même des caractères selon le modèle.
Embedding : Chaque token est converti en un vecteur numérique dense dans un espace de haute dimension (souvent 512 à 4096 dimensions), capturant sa signification sémantique.
Architecture Transformer : Le cœur du modèle utilise l’attention multi-têtes pour comprendre les relations contextuelles entre les tokens. Chaque couche transforme progressivement la représentation du texte.
Applications et Limites
Les LLM excellent dans :
- Génération de texte naturel
- Traduction automatique
- Résumé de documents
- Réponse à des questions complexes
Cependant, leur taille monumentale (milliards de paramètres) les rend coûteux en calcul et énergétiquement inefficaces pour des tâches spécialisées.
2. LCM (Large Context Models) : Maîtres de la Longue Distance
Innovation Architecturale
Les LCM résolvent le problème de la « mémoire courte » des LLM traditionnels grâce à des techniques avancées :
text
Sentence Segmentation → SONAR Embedding → Advanced Patterning → Quantization
SONAR Embedding (Sentence-Oriented Neural Attention Representation) : Contrairement aux embeddings token-par-token, cette approche capture la signification au niveau de la phrase, permettant une meilleure compréhension des documents longs.
Patterning Avancé : Identification de structures récurrentes dans les textes longs (patterns rhétoriques, structures narratives, cadres argumentatifs).
Cas d’Usage Spécifiques
- Analyse de documents juridiques (contrats de 100+ pages)
- Synthèse de rapports techniques complexes
- Surveillance de conversations étendues
- Recherche académique à travers de multiples articles
3. LAM (Large Action Models) : Du Langage à l’Action
Le Paradigme Neuro-Symbolique
Les LAM représentent une avancée majeure : des modèles qui comprennent ET agissent :
text
Input Processing → Perception System → Intent Recognition → Action Planning → Output
Système de Perception : Intégration multimodale combinant vision, langage et parfois données sensorielles.
Reconnaissance d’Intention : Distinction entre demande littérale et intention sous-jacente.
Planification d’Actions : Génération de séquences d’actions réalisables dans des environnements réels ou numériques.
Applications Révolutionnaires
- Assistants personnels exécutant des tâches complexes
- Automatisation de workflows métier
- Robots domestiques comprenant des instructions naturelles
- Systèmes de contrôle industriel intelligents
4. MoE (Mixture of Experts) : L’Approche Modulaire
Architecture à Routage Dynamique
Les modèles MoE fonctionnent sur un principe simple mais puissant : « diviser pour mieux régner » :
text
Router Mechanism → Expert Selection (Top-K) → Weighted Combination → Output
Mécanisme de Routage : Un réseau neuronal léger décide quels « experts » spécialisés doivent traiter chaque partie de l’input.
Sélection Top-K : Seuls K experts (généralement 2-4) sont activés pour chaque token, réduisant drastiquement les coûts computationnels.
Combinaison Pondérée : Les sorties des experts sélectionnés sont fusionnées selon des poids appris dynamiquement.
Avantages Décisifs
- Efficacité : Activation conditionnelle réduisant la consommation énergétique de 50-70%
- Spécialisation : Chaque expert développe une expertise dans un domaine spécifique
- Évolutivité : Ajout d’experts sans réentraînement complet du modèle
5. VLM (Vision-Language Models) : La Synergie Visio-Textuelle
Pont entre Deux Mondes
Les VLM créent un langage commun entre la vision par ordinateur et le traitement du langage naturel :
text
[Image Input → Vision Encoder] + [Text Input → Text Encoder] → Projection Interface → Multimodal Processor → Language Model → Output
Encodage Dual : Traitement parallèle des modalités visuelles et textuelles.
Interface de Projection : Alignement des représentations dans un espace sémantique commun.
Processeur Multimodal : Fusion profonde des caractéristiques visuelles et linguistiques.
Applications Transformatives
- Description d’images pour malvoyants
- Analyse de documents contenant texte et graphiques
- Réponse à des questions sur le contenu visuel
- Génération d’images à partir de descriptions textuelles
6. SLM (Small Language Models) : L’Efficacité par la Minimalisme
Optimisation Radicale
Les SLM prouvent que la taille n’est pas tout :
text
Compact Tokenization → Efficient Transformer → Model Quantization → Edge Deployment
Tokenisation Compacte : Vocabulaires optimisés pour des domaines spécifiques.
Transformers Efficaces : Architectures allégées (attention linéaire, couches partagées).
Quantisation Agressive : Réduction des poids de 32 bits à 8 voire 4 bits.
Révolution du Edge Computing
- Exécution sur smartphones et appareils IoT
- Temps de réponse inférieurs à 100ms
- Confidentialité des données (pas d’envoi cloud)
- Coût opérationnel négligeable
7. Modèles à Intégration de Feedback : L’Apprentissage Continu
Boucle d’Amélioration Perpétuelle
Ces modèles intègrent systématiquement les retours dans leur architecture :
text
Input Processing → Feedback Integration → Memory Optimization → Output Generation
Intégration de Feedback : Mécanismes pour incorporer les corrections, préférences et évaluations des utilisateurs.
Optimisation de Mémoire : Stockage sélectif des interactions pertinentes pour amélioration future.
Adaptation Contextuelle : Ajustement dynamique du comportement basé sur l’historique d’interactions.
Impact sur l’Expérience Utilisateur
- Personnalisation progressive sans réentraînement complet
- Correction d’erreurs systématiques
- Adaptation aux préférences individuelles
- Amélioration continue des performances
8. Modèles de Segmentation d’Images : La Vision Granulaire
Décorticage Visuel
Spécialisés dans la compréhension fine des images :
text
Image Input → Image Encoder → Feature Correlation → Mask Decoder → Segmentation Output
Encodage d’Images : Extraction de caractéristiques à plusieurs niveaux de granularité.
Corrélation de Features : Identification des relations spatiales et sémantiques entre régions.
Décodage de Masques : Génération de délimitations précises pour chaque objet ou région.
Applications Critiques
- Diagnostic médical (détection de tumeurs)
- Véhicules autonomes (segmentation de la scène routière)
- Analyse satellite (détection de changements environnementaux)
- Réalité augmentée (compréhension de l’environnement)
Tableau Synoptique : Comparaison des Huit Architectures
| Modèle | Paramètres Typiques | Force Principale | Cas d’Usage Idéal | Coût d’Inférence |
|---|---|---|---|---|
| LLM | 7B-1T+ | Génération de texte naturel | Assistants conversationnels | Élevé |
| LCM | 10B-100B | Contexte long | Analyse documentaire | Modéré-Élevé |
| LAM | 20B-200B | Exécution d’actions | Automatisation de tâches | Variable |
| MoE | 100B-1T+ (sparse) | Efficacité computationnelle | Applications à grande échelle | Faible (par token) |
| VLM | 3B-100B | Compréhension multimodale | Analyse image-texte | Modéré |
| SLM | 100M-3B | Déploiement edge | Applications mobiles | Très faible |
| Feedback Models | Variable | Amélioration continue | Systèmes interactifs | Variable |
| Segmentation | 500M-10B | Précision visuelle | Applications médicales/robotiques | Modéré |
Tendances Futures et Implications
1. Hybridation des Architectures
La frontière entre ces modèles s’estompe. Nous voyons émerger des architectures hybrides comme les MoE incluant des experts VLM, ou des LLM intégrant des capacités de segmentation.
2. Spécialisation Verticale
L’avenir appartient aux modèles spécialisés par industrie : LLM juridiques, VLM médicaux, LAM manufacturiers, chacun optimisé pour le jargon, les processus et les exigences spécifiques à leur domaine.
3. Économie des Modèles
Le coût différencié des architectures permet une optimisation économique. Les entreprises peuvent désormais sélectionner l’architecture la plus rentable pour chaque tâche spécifique.
4. Accès Démocratisé
Les SLM et techniques d’efficacité rendent l’IA avancée accessible aux PME, aux chercheurs indépendants et aux pays en développement.
Guide de Sélection : Quel Modèle Choisir ?
Pour le Service Client
Recommandation : LLM + Feedback Integration
Justification : Compréhension conversationnelle avec amélioration continue basée sur les interactions.
Pour l’Analyse Financière
Recommandation : LCM + MoE
Justification : Traitement de longs rapports avec activation sélective d’experts spécialisés (comptabilité, marché, régulation).
Pour la Robotique
Recommandation : LAM + Segmentation
Justification : Compréhension d’instructions naturelles avec perception visuelle précise de l’environnement.
Pour les Applications Mobiles
Recommandation : SLM optimisé
Justification : Confidentialité des données, faible latence, fonctionnement hors-ligne.
Conclusion : Vers un Écosystème Symbiotique
La spécialisation des modèles d’IA ne représente pas un éclatement du domaine, mais plutôt une maturation. Tout comme en biologie où différents organes se spécialisent pour des fonctions spécifiques tout en collaborant harmonieusement, les différentes architectures d’IA développent des expertises complémentaires.
L’avenir de l’intelligence artificielle réside dans l’orchestration intelligente de ces modèles spécialisés. Des systèmes de routage sophistiqués (eux-mêmes basés sur des modèles MoE) dirigeront automatiquement chaque requête vers l’architecture la plus adaptée, créant ainsi une intelligence collective plus performante, plus efficace et plus polyvalente qu’aucun modèle unique ne pourrait jamais l’être.
Cette diversification représente également une opportunité stratégique majeure pour les entreprises et les développeurs. Plutôt que de chercher le « modèle universel », la clé du succès réside désormais dans l’identification des combinaisons architecturales optimales pour des cas d’usage spécifiques.
L’ère de l’IA monolithique s’achève. L’ère de l’IA spécialisée, diversifiée et synergique commence.
FAQ : Comprendre les Modèles d’IA Spécialisés
Section FAQ Intégrée à l’Article
❓ Questions Fréquentes sur les Modèles d’IA Spécialisés
Q1 : Pourquoi avoir besoin de modèles spécialisés alors que les LLM comme ChatGPT fonctionnent si bien ?
R : C’est une question d’efficacité, de coût et de performance spécifique. Imaginez un couteau suisse vs des outils spécialisés : le couteau suisse fait beaucoup de choses correctement, mais un scalpel chirurgical, un tournevis professionnel ou un couteau de chef font chacune de ces tâches beaucoup mieux. Les LLM généralistes gaspillent des ressources computationnelles énormes pour des tâches simples, tandis que les modèles spécialisés offrent :
- Des performances supérieures de 30-70% dans leur domaine
- Des coûts d’inférence réduits de 50-90%
- Une latence bien inférieure
- Une consommation énergétique optimisée
Q2 : Les MoE sont-ils vraiment plus efficaces que les LLM traditionnels ? Comment fonctionne cette magie ?
R : L’efficacité des MoE repose sur un principe simple mais brillant : l’activation conditionnelle. Plutôt que d’utiliser tous les « neurones » du modèle pour chaque traitement (comme un LLM traditionnel), un routeur intelligent sélectionne seulement 2-4 experts spécialisés parmi des centaines disponibles. Concrètement :
- Pour une question médicale : activation des experts « terminologie médicale » + « raisonnement diagnostic »
- Pour une question légale : activation des experts « droit » + « analyse contractuelle »
- Pour un problème mathématique : activation des experts « calcul » + « raisonnement logique »
Cette approche réduit drastiquement les calculs nécessaires sans sacrifier la qualité.
Q3 : Quelle est la différence fondamentale entre un LAM et un LLM ?
R : La différence est philosophique et technique :
| Aspect | LLM (Large Language Model) | LAM (Large Action Model) |
|---|---|---|
| Objectif | Comprendre et générer du texte | Comprendre et exécuter des actions |
| Sortie | Texte / Code | Séquences d’actions exécutables |
| Architecture | Transformer linguistique pur | Système neuro-symbolique hybride |
| Capacité | Savoir « quoi dire » | Savoir « quoi faire » |
| Exemple | « Voici les étapes pour réserver un vol » | Réserve effectivement un vol |
Les LAM intègrent un module de planification et un système d’exécution absents des LLM.
Q4 : Les SLM peuvent-ils vraiment rivaliser avec les grands modèles ? Dans quels cas ?
R : Oui, mais dans des niches spécifiques. La loi des rendements décroissants s’applique aux modèles d’IA : après un certain point, doubler la taille n’améliore que marginalement les performances. Les SLM excellent particulièrement dans :
- Tâches déterministes : Correction grammaticale, reformulation, extraction d’information structurée
- Domaines restreints : Support client pour un produit spécifique, FAQ spécialisée
- Environnements contraints : Applications mobiles, IoT, edge computing
- Cas nécessitant confidentialité : Traitement local sans données envoyées au cloud
Un SLM de 3B paramètres bien entraîné sur un domaine spécifique peut surpasser un LLM de 100B paramètres généraliste pour cette tâche précise.
Q5 : Comment les LCM gèrent-ils les documents très longs que les LLM traditionnels ne peuvent pas traiter ?
R : Les LCM utilisent plusieurs innovations techniques :
- Mémoire Hiérarchique : Au lieu de traiter 100 000 tokens comme une séquence plate, ils créent une structure arborescente avec des résumés à différents niveaux.
- Attention Sparse : Ils ne calculent pas l’attention entre tous les tokens (trop coûteux), mais seulement entre les tokens « importants » identifiés dynamiquement.
- Compression Contextuelle : Les parties moins pertinentes sont compressées (comme un .zip sémantique) et décompressées seulement si nécessaires.
- Mécanismes de Référence : Comme les notes de bas de page dans un livre académique, ils créent des références croisées entre sections distantes.
Q6 : Les VLM remplaceront-ils les modèles purement visuels (comme les CNN) ?
R : Pas complètement, mais ils changent la donne. La complémentarité persiste :
- Pour la classification simple : « Cette image contient-elle un chat ? » → Les CNN restent plus efficaces
- Pour la compréhension complexe : « Décris cette scène de rue en détail, incluant les interactions entre piétons » → Les VLM sont imbattables
- Pour les tâches multimodales : « À partir de ce graphique et du texte associé, explique les tendances » → Seuls les VLM peuvent le faire
L’avenir est aux architectures hybrides qui utilisent le bon outil pour chaque sous-tâche.
Q7 : Quel est le principal défi technique des modèles à intégration de feedback ?
R : Le défi fondamental est l’équilibre entre adaptation et stabilité. Un modèle qui s’adapte trop aux feedbacks individuels risque :
- L’oubli catastrophique : Oublier ce qu’il savait avant
- La sur-adaptation : Devenir trop spécifique à un utilisateur
- La manipulation : Être détourné par des feedbacks malveillants
Les solutions actuelles incluent :
- Mémoire différentiée : Séparation stricte entre connaissances de base et adaptations
- Validation croisée : Nécessité de feedbacks cohérents avant adaptation
- Limites d’influence : Bornes sur l’ampleur des changements possibles
Q8 : Comment choisir entre architecture MoE et architecture classique pour mon projet ?
R : Utilisez ce guide de décision :
Choisissez MoE si :
- Votre application traite des types de requêtes très diversifiés
- Vous avez des pics de charge imprévisibles
- Le coût computationnel est une préoccupation majeure
- Vous pouvez définir clairement des « domaines d’expertise »
Choisissez une architecture classique si :
- Vos tâches sont homogènes et spécialisées
- Vous avez besoin d’une latence ultra-prévisible
- Vous disposez de ressources computationnelles stables
- La simplicité d’implémentation prime
Cas intermédiaire : Commencez par une architecture classique, mesurez les patterns d’utilisation, puis migrez vers MoE si vous identifiez des clusters naturels de requêtes.
Q9 : Les modèles spécialisés ne vont-ils pas fragmenter l’écosystème IA ?
R : C’est un risque réel, mais des standards émergent pour l’atténuer :
- Interfaces unifiées : APIs standardisées (comme OpenAI pour les LLM)
- Formats d’échange : Standards comme ONNX pour l’interopérabilité des modèles
- Orchestrateurs intelligents : Systèmes qui routent automatiquement vers le bon modèle spécialisé
- Architectures modulaires : Plug-and-play des composants spécialisés
La fragmentation actuelle rappelle les débuts de l’informatique, avant la standardisation. Elle devrait conduire à une consolidation autour des approches les plus efficaces.
Q10 : Quel est le prochain grand saut après la spécialisation actuelle ?
R : La prochaine frontière est l’orchestration intelligente multi-modèles. Imaginez :
- Un meta-contrôleur qui analyse chaque requête
- Une bibliothèque dynamique de modèles spécialisés
- Un système de composition qui combine plusieurs modèles pour des tâches complexes
- Un mécanisme d’apprentissage qui crée de nouveaux experts spécialisés à la demande
Nous évoluons vers des systèmes d’IA collectifs où différentes intelligences spécialisées collaborent, exactement comme dans une équipe humaine pluridisciplinaire.
💡 Pour Aller Plus Loin
Vous développez une application IA ? Posez-vous ces questions :
- Mes utilisateurs ont-ils des besoins très diversifiés ou homogènes ?
- La latence ou le coût est-il mon principal défi ?
- Ai-je besoin de traitement local ou le cloud est-il acceptable ?
- Mon domaine nécessite-t-il une compréhension profonde ou des réponses rapides ?
Les spécialistes recommandent : Commencez simple avec un modèle généraliste, instrumentez finement son usage, identifiez les patterns, puis spécialisez progressivement. La spécialisation prématurée est aussi risquée que la généralisation excessive.
Cette FAQ évoluera avec les avancées technologiques. Dernière mise à jour : Février 2026